Introduction
The Multifamily Housing Database (MFHD) was created with the goals of: i) automating the process of producing quarterly BIP reports, ii) standardizing the collection and storage of data on multifamily rentals in NYC, and iii) organizing the decade plus of historical data collected through BIP to make available for research and analysis. The MFHD allows for the possibility of a number of added elements to UNHP’s data work, including:
• The ability to more easily compare trends over time in the decade-plus worth of data in BIP. This is especially relevant for analysis of pricing, speculation, and predatory tactics on the part of landlords, as our research has shown that speculative behavior is best grasped by examining multi-year patterns.
• The ability to access more detailed information than has been traditionally maintained in our quarterly BIP excel files. For instance, while BIP currently only captures the count of active DOB violations, the MFHD will allow for storage and easy analysis of subsets of DOB violations that might be relevant to organizers or lenders.
• The ability to quickly incorporate new datasets into the MFHD. Just this year, new and relevant datasets came onto the NYC Open Data Portal on subjects like eviction warrants executed or J-51 tax abatements. The code for the MFHD is easily adjustable in order to interact with new datasets, which allows us to migrate and provide access to new data in a format that is digestible for our users.
• The ability to provide up-to-date data on buildings in the BIP database. Currently, we update and send out BIP data quarterly. However, the MFHD will update with any new data at regular intervals, and partners who prefer to see any changes in violation counts or financing data as soon as they occur can have access to that capability in a familiar Excel format.
• The ability to serve as a back-end for other housing data tools. By virtue of UNHP’s long history collecting data and institutional expertise, the data tools that housing advocates and lenders use would benefit immensely from access to BIP data. The MFHD is structured using common data architecture, allowing academics, civic tech activists, and other stakeholders to access customized ‘slices’ of the data when appropriate.
Guide Summary
In this guide you will find a summary of the data structure used for the Building Indicator Project (BIP). The summary assumes that the reader has experience with the world of NYC housing data (particularly Open Data), and is intended to help users of the MFHD understand the potential applications of BIP data and their limitations. The data summary is divided into five parts:
1. Processed BIP Data – in this section, we lay out how the data sources that get automatically updated in our SQL Server are transformed into a format consistent with Building Indicator Project quarterly releases. This section focuses on key differences between pre- and post- implementation of the MFHD. We also provide descriptions of the source data used to arrive at BIP quarterly reports. In many cases, these source tables are already processed versions of the raw data that are available through NYC Open Data or the sites from which we scrape data. Those transformations are described.
3. Other Sources – in this section, we provide context for data sources not in BIP but of relevance to our users.
4. Data Management – in this section, we provide context on our management tables in the MFHD, as well as other data infrastructure that allows us to process and keep track of the data we collect.
5. Introduction to SQL Server – in this section, we provide a brief overview to SQL, including best-practices in constructing queries in the MFHD that produce results quickly and efficiently.
How to Access MFHD SQL Server
In order to access the MFHD, you must request a username and password by sending an email to bip@unhp.org. The email should include a brief description of the intended use of the data. Please note that we do not provide access to the MFHD for for-profit uses, and do not have capacity to provide technical support beyond what is provided in the documentation in the MFHD Guide.
Processed Data
BIP Report
The most important table in the MFHD SQL Server is final.bip_report, which contains all processed BIP data for each release of the database going back to 2008. As of the beginning of 2020, there have been 34 runs of BIP, each of which provide snapshots of data on all buildings in the database at (more or less) quarterly intervals. Each run captures what we think of as the universe of multifamily buildings at any given time, defined by building classification and properties that contain five or more residential units, according to publicly available data.
The BBL – a 10-digit concatenation of the borough, block, and tax lot – is used to represent a building1 as most city datasets contain BBL or its constituent parts. Since the final.bip_report table contains data from 2008 on, BBLs have multiple rows in the table – one for each quarterly run of BIP that the BBL has been included in. For this reason, the primary key of the final.bip_report table is a concatenation of [bbl] and [run_code].
While the majority of BBLs have been in BIP since its inception, there are BBLs that have either entered or exited BIP since 2008. These BBLs will only have rows for some of the run_codes– this occurs when a property enters or exits the multifamily universe, or when a property’s BBL changes.2 All in all, there are ~ 75,000 properties that have at one point or another been in the BIP database. Out of the properties, ~ 59,000 have been in runs of BIP at least 30 times, and the majority of those properties that have been in the database less than 30 times are condo BBLs, which were only included in BIP from 2019_q2 forward. We keep track of which BBLs are part of the multifamily universe at the time of each run through what we call basefiles. Before 2019, those basefiles were updated every two years, and after 2019 they are updated every half-year.
final.bip_report compiles data from multiple city datasets. Before 2019, the BIP team was manually processing the sources of data that make up the BIP database and only storing the final product in Excel format – similar to the excel files that are sent out to our partners quarterly. However, the city has created the Open Data API where the needed datasets are published and regularly updated. Because of this, the process by which we collect and store housing data changed dramatically at the beginning of 2019. Now, the MFHD stores all data from the sources that make up the BIP database and automatically appends incremental changes or new rows on a daily, weekly, or monthly basis, depending on the frequency with which the city publishes updates.
final.bip_report is a combination of data that was collected through our old system, and data that is appended to the MFHD automatically in our new system. For [run_code] 2008_q1 through 2018_q4, the aggregate data was compiled and uploaded to the MFHD from static Excel files into a table called source.historical.bip.combined. We combine the historical data with new BIP data each quarter using a query that updates final.bip_report to include the newest [run_code] as well as all historical data (pre and post- 2019).
Importantly, this means that we sometimes only have stored aggregate (i.e. rolled up) data on certain sources before the implementation of the MFHD system, whereas after the beginning of 2019 we store disaggregated data for all sources that we track. In cases where the historical data are still available via NYC Open Data, we have stored both the disaggregated Open Data and the processed and aggregated BIP data. However, in sources where that data no longer exists publicly, we are only able to access the processed and aggregated BIP data. More on that on the BIP Sources page.
One more note about final.bip_report. The table does not include any data that fall under the categories of a) building description (age of building, zoning, etc.) or b) geographies (census tract, political districts, etc.). For pre-2019 data that fall under either of those categories, the data exist in source.historical.bip.combined. However, after the implementation of the MFHD, that data is stored in basefile tables, which as of the date of this document, includes the tables source.BIP_basefile_2019_1 and source.BIP_basefile_current. The current basefile table is joined to final.bip_report to produce the Excel file that holds each run of the BIP database.
ACRIS
In the Open Data, ACRIS is made up of three tables that we join together in our final.acris table, which brings all the data on each [document_id] into a row. For a [document_id] that applies to multiple properties, there are multiple rows for each [document_id] (one for each [bbl]). In final.acris, then, a unique ID field would be a concatenation of [document_id] and [bbl]. The final.acris table is updated monthly, on the same day that the Open Data source is updated.
Because of inconsistencies in the historical BIP data that refers to property financing, we do not rely on ACRIS data from source.historical.bip.combined. Instead, we rely solely on ACRIS Open Data, which is possible because ACRIS Open Data contains all historical financing documents. The final.acris table compiles all historical documents for every property in the ACRIS database available via Open Data, and is thus an extremely large table that is cumbersome to query. For that reason, we have multiple ACRIS sub-tables that are updated each time final.acris is updated. The sub-tables are:
• final.acris_bip – This filters the final.acris table for BBLs that have been in our BIP database (again, approximately 75,000).
• final.acris_bip_current – This filters the final.acris_bip table for the latest financing document of a certain type for each BBL in our BIP database at the time of the latest run code. There are many different document types in ACRIS data, which are referenced in the [doc_type] field. For the purposes of BIP data releases, we are interested only in a subset of those document types that help us best understand which financial institution is the most recent holder of debt on that property. For more, see the Umbrellas section below.
• final.acris_bip_history – This filters the final.acris_bip table into the latest financing documents of a certain type for each of the 34 runs of BIP in the BIP database. In other words, it is an expanded version of final.acris_bip_current, but with data for each BBL that represents the latest financing document at the cutoff date of a certain run code.
• final.acris_bip_deeds – This filters the final.acris_bip table for all documents with a deed [doc_type]. Since this table is created from final.acris_bip, it only contains data for BBLs that have been in BIP. Deeds document any transfer of title of property, either a sale or a non-sale transfer.
• final.acris_bip_deeds_edited – This filters the final.acris_bip_deeds table into only those deeds that we think are likely to represent actual sales. This table takes into account a number of fields in the ACRIS data to make this distinction, including [document_amt] and [percent_transferred]. Statistical methods are used to filter out deeds that are unlikely to represent building sales.
The final table that relates to ACRIS data is the final.umbrellas table, which is a lookup table of ACRIS party names and financial institutions that are associated with those party names. In ACRIS financing and sales data, there are always at least two parties to a document – a mortgagor (debtor) and mortgagee (creditor), or a buyer and seller – and sometimes more. The BIP database tracks the multifamily portfolios of financial institutions (bank and non-bank) by tracking those party names; in fact, the financial institutions that receive BIP data only receive their portfolio’s data, which is our best guess of all multifamily properties for which a given financial institution holds the latest senior debt.
In order to match party names to financial institutions, we need a lookup table that accounts for a) variations or misspelling in party names, b) subsidiaries, and c) mergers and acquisitions over time. All in all, the final.umbrellas lookup table tracks approximately 3,400 party name variations for some 330 financial institutions.
HPD Violations, Complaints, and Problems
HPD violations are one of the two major groups of violations that we use in the BIP database. HPD violations are breaches of the Housing Maintenance Code that have been confirmed by an inspector’s site visit to a particular property.
The table final.hpd_violations contains all available data through the Open Data API, with detailed information about each individual violation. This data was made available in 2014, and is updated daily – the MFHD automatically tracks all changes in the data. The Open Data has theoretically included all violations since 2014, as well as some historical data. However, the completeness of pre-’14 data, as well as the data made available in the first few years after 2014, needs to be analyzed.
Beginning with the 2019_q1 [run_code], the final.bip_report table relies upon the disaggregated data available in final.hpd_violations. Before that run of BIP, the data we use is filtered and aggregated to get the count of all active violations as well as the count of all active violations that were issued in the 12 months prior to the run of BIP. These counts are separated by violation class which is an indicator of the severity of the violation – A is the least serious and C is the most serious.
HPD complaints is a database of tenant complaints submitted to 311 and directed to HPD because they pertain to the Housing Maintenance Code. An HPD complaint turns into an HPD violation upon a City inspector’s confirmation of the issue. HPD violations can be thought of as a subset of HPD complaints, and the tables share the [Complaint_ID] key to trace whether certain complaints turn into violations. There can be multiple HPD violations for each HPD complaint.
Like the final.hpd_violations table, the final.hpd_complaints table contains all available data through the Open Data API from 2014 to the present, including some historical data. HPD complaints data from pre-’14 and data from the first few years of the Open Data program would need to be analyzed for completeness.
The final Open Data source relevant for HPD violations is the HPD complaint problems table. This table lists all the issues recorded by a 311 operator during a call that lead to an HPD complaint. For this reason, there can be multiple problems associated with each complaint. HPD complaint problems have not yet been brought into the MFHD, but easily could be depending on the needs of particular users. This table would be linked to the other two tables via the [Complaint_ID] key.
DOB & ECB Violations and Complaints
DOB violations are the second of the two major groups of housing violations that we track in the BIP database. DOB violations are breaches of the Building and Construction Codes as well as zoning resolutions, and are also confirmed by an inspector’s site visit to a property.
ECB violations are a subset of DOB violations, and refer to instances where a violation requires an order to certify correction of the problem and at times an OATH hearing4. ECB violations are divided into three classes (1 = immediately hazardous, 2 = major, 3 = lesser) and also come with money penalties if violations are not corrected in the time allotted, according to the violation class.
The tables final.dob_violations and final.ecb_violations contain all available data through the Open Data API, with detailed information about each individual violation. This data was made available at the end of 2015, and is updated daily – the MFHD automatically tracks all changes in the data. The tables are linked by a field referred to as [Violation_Number] in final.dob_violations and [DOB_Violation_Number] in final.ecb_violations. Every row in the ECB violations table will have a corresponding row in the DOB violations table.
Beginning with the 2019_q1 [run_code], the final.bip_report table relies upon the disaggregated data available in final.dob_violations and final.ecb_violations. Before that run of BIP, the data we use is filtered and aggregated to get counts of active DOB and ECB violations by property; for ECB violations, there is no reference to class or money penalty in the historical BIP data. While the Open Data for these sources goes back to the end of 2015, as noted in the previous section, completeness analysis would have to be conducted before relying upon older data.
DOB complaints is a database of tenant complaints submitted to 311 and directed to DOB because they pertain to building & construction codes or zoning. An DOB complaint turns into an DOB (or ECB) violation upon a City inspector’s confirmation of the issue. The Open Data API contains DOB complaints data from 2013 to the present, but currently the data is not in the MFHD. We have also not identified an ID field that connects individual DOB complaints to individual DOB violations.
DOF Liens
The Department of Finance publishes data regarding unpaid charges and overdue taxes on every property in NYC. This data is not available via Open Data; instead, since 2008, we have used a web scraper to gather this data from City-managed lookup sites. These lookup sites show the individual charges a building owes once a BBL or address is entered in. The web scraper connects to the SQL server in order to get the list of BBLs to run through the lookup site.
For data prior to the 2019_q1 quarterly run of the BIP database, we use aggregated financial lien data by property from the source.historical.bip.combined table. This tracks the total amount of overdue charges and taxes by property. It also identifies the total amount of those charges which are due to the Emergency Repair Program (ERP). ERP charges are incurred when a property owner fails to correct a hazardous violation in a timely manner, and the City contracts out the repair and then charges the owner. Since 2019_q1, however, the MFHD stores disaggregated data on all BBLs in the database as well. This disaggregated data is automatically appended to the final.dof_scraped table following quarterly runs of the web scraper.
DEP Water
Overdue water payments are another of the financial liens that is collected in the MFHD. Unpaid water charges are transferred to UNHP by DEP directly, and for that reason must be uploaded manually into the MFHD each quarter. The water data for each quarter are appended to the final.water table. Data from before 2019_q1 are included in the source.historical.bip.combined table, apart from a gap between 2013 and 2014. This was the period when we were no longer able to scrape for water data from a publically available lookup site and had not yet come to an agreement with DEP to access water charge data directly.
HPD Registration
All multifamily building owners are required to register their property with HPD, listing the names and addresses of managers, owners, and officers in the entity that owns the property.5 HPD Registration combines two sources from the Open Data API, Contacts and Multiple Dwellings. Contacts contain the names and addresses of the people who the property is registered to. There are multiple rows per BBL – one for each [type] of registration (head officer, agent, etc.). Multiple Dwellings have property information (BBL, address, etc.) as well as the date the registration was filed. There are multiple rows per BBL as building registrations are supposed to be updated yearly or when there is a change of ownership.
In the Open Data, the rows in these two sources are overwritten each time a property submits a new registration. However, the table final.bip_registration tracks and stores all changes to registration data, so that ownership information over time is available. Moreover, the source.historical.bip.combined table contains HPD registration information dating back to 2008, which is not available via Open Data.
Building Lists & Geographies
The following data are binary indicators for each property in BIP at each [run_code]:
- 421a – does a property actively receive a 421A tax exemption?
- J51 – does a property actively receive a J51 tax abatement of exemption?
- CONH – is a property part of the Certificate of No Harassment pilot program?
- Rent Stabilization – has a property appeared on at least one list of rent-stabilized buildings (defined as having 1+ rent-stabilized units) since 2016? Identified using ’16 and ’17 rent-stabilized buildings list from RGB, as well as civic-tech scrape of tax bills (for more, see: https://github.com/talos/nyc-s…)
- NYCHA – is a property owned by NYCHA? The name of the NYCHA development given as well
- HDFC – is a property an Article 11 building (either non-profit owned or a limited equity co-op)? HDFC data are not available directly, so buildings are identified using string searches of ownership data. This data is therefore subject to some error.
- AEP – is a property actively part of the Alternative Enforcement Program?
Below is a list of the various geographies that we capture for each property in our database. The geographies are transformed into tabular data (i.e. each property is identified by the numeric ID of a political district or tract) and stored in our basefile tables. Tabular data on other desired geographies can be easily added to the MFHD as long as shapefiles exist for the geographies in question.
• Tax Lot (BBL) Address
• Zip Code
• Census Tract
• City Council District
• State Senate District
• Congressional District
• LMI Tract
• Opportunity Zone Tract
• State Assembly District
Other Sources
The below includes detail on important data sources for NYC housing that have been or can be brought into the MFHD for analysis:
NYCDB
The NYC Housing Data Coalition (HDC), of which UNHP is a part, is a group of data-minded staff and volunteers within the NYC housing movement. HDC conducts analysis on behalf of community-based organizations, and also provides technical infrastructure and support for academic or policy work. The major tool that HDC makes available is NYCDB, which is an open-source, cloud-based SQL database very similar to the MFHD. However, there are a number of sources in NYCDB not in the MFHD, most of which are expanded upon below. All NYCDB data can be brought into the MFHD upon request for the purposes of analysis.
Eviction Data
Data on evictions come from a number of sources, each of which capture different points along an eviction process. Theoretically, each NYC eviction case that ends in an actual eviction starts with an eviction filing in a county court and ends with an eviction warrant executed by a City Marshal, with a number of possible steps in between.
The final step in that process – eviction warrants executed – is captured by an NYC Open Data dataset managed by the Department of Investigations (DOI). DOI, however, does not clean the address field (which is entered manually from Marshal notes) and also does not geocode the data with a BBL or lat long. Together with HDC, we work to clean this data periodically for analysis. These data are not in the MFHD currently, but can be geocoded and brought for any period upon request. DOI evictions data are available from 2017 and forward, updated on a daily basis.
Other data on evictions – from eviction filings through to eviction judgments – are stored and managed by the NYS Office of Court Administration (OCA). There is a long history of use and misuse of this data – especially for the purposes of tenant blacklisting – and as such it is very difficult to access. However, through an advocacy effort also led by HDC and allied organizations, we are working towards accessing that data as well. We already have access to case-level de-identified (i.e. without address) data, which can be used through NYCDB. De-identified data allows for tracking the process of an individual case through housing court, with the most granular geographic identifier being zip code. As such, it is only useful for aggregate analysis, or as a control for other variables. This data is available from 2016 forward, and has a complex data structure that is currently being documented by HDC volunteers (see here for more). HDC is also working to get access to identified housing court data from OCA, though this requires the signing of a security agreement and limits analysis to permitted uses defined through a legal agreement with the OCA.
Rent Stabilization Data
The data on the number of rent-stabilized units in rent-regulated buildings is maintained by NYS Division of Homes and Community Renewal and is not made publicly available. However, the mid-year Department of Finance property tax bill for NYC multifamily properties does list a self-reported count of rent-stabilized units in a building. This is because that mid-year bill includes a registration fee of $10 per rent stabilized units. The PDFs of those tax bills are publicly available through a lookup site.
A civic tech activist associated with HDC scrapes those PDFs annually to get the change in self-reported counts in multifamily buildings year-over-year (for more, see the github repo here). These data are available through NYCDB from 2007 to the present.
While these data are an important source and are included in a number of different housing data tools, the data are problematic because they are self-reported, and we know that there is rampant fraud and under-reporting of stabilized units. Additionally, they are also extremely noisy, meaning that the year over-year changes in rent-stabilized counts in a given building often don’t make much sense. Because we have not had capacity to analyze these issues statistically, we have hesitated in using this source in our BIP data releases. However, for users with the resources to do so, rent stabilization data can be brought into the MFHD upon request.
CoreData (Furman Center)
The Furman Center makes available the Subsidized Housing Database, which, “includes the only publicly available, property-level database of New York City’s subsidized housing. It allows users to identify currently subsidized properties in the city, the subsidy type and program applicable to specific properties, and the start and end date for the subsidy on a property, allowing the user to identify properties at risk of exiting from affordability restrictions.” This data can be brought into the MFHD upon request.
Data Management
Helper Tables and Stored Procedures
The following are helper tables or stored procedures (i.e. queries run in our data pipelines) that might be useful to users of the BIP Server, especially in query joins.
- source.run_code_dates
This table associates a specific date – the end date of each run_code – with each run of BIP, and also indicates the current run of BIP in a binary column.
- source.bip_bbl_runcode
This table associates each BBL with a [res_unit] at a specific point in time, signified by [run_code], starting in 2019. This means that, as of early 2020 each property in BIP can have a maximum of four rows in this table.
- source.bip_all_bbls
This table contains every BBL that has ever been in the Building Indicator Project.
- etl.bip_report
This is a stored procedure that generates the final.bip_report table each quarter for every [run_code] in BIP. This means that the stored procedure needs to handle both the BIP data from runs that predate the SQL server (2008_q1 – 2018_q4) as well as the runs moving forward (2019_q1 on).
Management Tables
These are tables that we use to store organizational information such as table names and run_code dates. They help us manage the relationships between the many tables.
- Etl.params
Keeps track of Open Data table names & API identifiers, date last updated, and whether or not the table is staged. Information from this table is used as parameter values that are fed through the checkLastUpdated function, the dev function, and the dynamic-opendata-get-incremental-clean notebook which are executed when updating the Open Data, ACRIS, and HPD Registration pipelines. The [date_last_updated] column in etl.params is automatically updated for tables that have new data appended.
- source.run_code_dates
Keeps track of [run_code] end dates and tracks the current run of BIP. There are two columns with modified end dates – [start_date_hpd] for hpd registration and 421a & [modified_start_date] for AEP, DOB violations, ECB violations, HPD violations, Complaints, J51, and rent stabilization.
*Note, the columns in this table have misleading names. The dates are actually the end date for each [run_code], not the start date.
*Ideally, this table would be in the etl schema
- source.bip_bbl_runcode

This table is updated manually when the basefile changes. It has three columns [BBL], [res_unit], and [run_code]. The table is used to implicitly tie run_codes (from 2019-q1 on) to the basefile that was/will be used. It is used in etl.bip_report so that we do not have to edit the stored procedure every run.
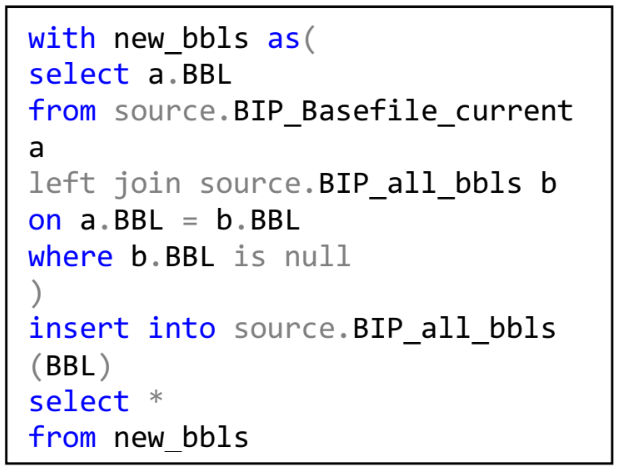
Whenever the basefile is updated (biannually) this table needs to be updated as well. Use the code to the right to do so. Replace the names of the old runs with the run_codes that will be associated with the new basefile. Ensure that source.BIP_Basefile_current has been updated before you do this.
In the example above, the BBLs from the updated basefile are being assigned to the first two quarters of 2019.
Important Tables
- source.historical_bip_combined
This table was created by compiling all of the old BIP excel sheets. It contains [run_code] 2008_q1 – 2018_q4. It is used to fill in historical information when creating final.bip_report since some data is not available through Open Data – many of the tables made available do not go as far back in time as the BIP reports do.
To see the columns included in each [run_code], go to the excel workbook Historical BIP Combined Columns in this folder. A ‘1’ indicates that the column was included in the specified run of BIP, a ‘0’ indicates that it was not.
*Note, this table has the old ACRIS information in it NOT the audited/correct data which is in final.acris. final.acris has the ACRIS data for all run_codes.
- final.bip_report
This table contains all run codes of BIP. It has all of the BIP columns except for the basefile columns and the following calculated columns [Open_Violations], [PriorYear_Violations], [PY_V_to_C_Ratio], [Occurance], [Average], and [CDFAvg]. It does include [res_unit] and calculates the three scoring columns [Absolute], [per_unit], and [current_BIP_score]. See the final.bip_report section below for more information.
- source.bip_all_bbls
This table contains all BBLs that have ever been in BIP. It is used in etl.bip_report so that the Stored Procedure does not need to be edited for each run of BIP. The table should be updated every time source.BIP_Basefile_current is changed using the code below.
Data Schemas
The tables in the BIP Database are organized into three main schemas source.____ , stage.____, & final.____. These schemas are used to organize the different versions of the datasets that we store.
The source schema contains tables in their original form – that is how they are in Open Data or the source CSV. The tables in the stage schema are created by stored procedures. Not every dataset will have a stage table, only those that need to be transformed / modified in some way will. The tables in the final schema have been organized so that they can be easily joined with others in the relational database.
There are also two other important schemas: the etl.___ schema and the dbo.___ schema. The etl schema contains the Stored Procedures as well as the etl.params management table. The dbo schema contains all of the Views.
New schemas can be created as needed to keep new tables organized.
System-Versioned Tables
These tables are used when incremental data updates modify existing rows instead of adding new ones. The system versioned table will keep the historical row of data and create a new row with the updated information.
- e.g. dob_violations – when a violation is closed, Open Data will register a change of status in the original row of the Open Data table. The system versioned table in the final schema of the UNHP SQL Server will maintain the old row, where the status is open, and create a new row, where the status is closed. The old row will be stored in the history.dob_violations table while the new row will be stored in the final.dob_violations table.
System-versioned tables will have [row_start_date] and [row_end_date] columns which contain the dates through which the data in the row was valid (in other words, until the update date). This makes it possible to query for different time periods. System-versioned tables must have a primary key, a column with unique values in every row.
If you want to query both the historical and the current data, you need to use a system_time all statement. See Important Query Syntax below.
Stored Procedures
Stored procedures use Transact-SQL. They are static queries which are called by steps in our data pipeline that allow us to automate the movement of data from the source tables to the stage & final tables. When a table does not need to be staged, the stored procedure simply moves all of the rows from the source table into the final table. When a table does need to be staged, the stored procedure contains a query to shape the data into its desired form. It may join multiple tables together or return a subset of the columns and/or rows from the source table.
Stored procedures are organized into the etl schema. They can be found under the Programmability folder in the SQL server.
*Note, when writing Stored Procedures to move data from the source to the final table, use a MERGE statement if the table is system-versioned.
Views
These are virtual tables that are not permanently stored in the database; they are made from queries of the other tables. They are useful for a few reasons: they save complicated / frequently used queries and, if we grant database access to subscribers, we can restrict their access to views we create instead of letting them access the underlying tables.
Views are saved in the dbo schema. They can be found in the Views folder in the SQL server.
Backend Overview
[write overview of BIP server backend for this audience]
Introduction to SQL Server
Relational Database
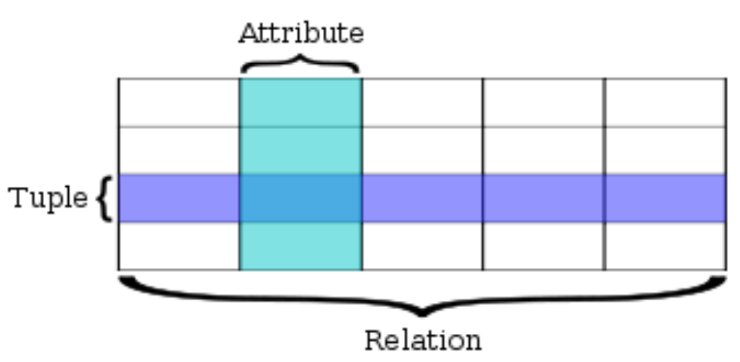
A database is a collection of related data that has been organized into tables. Tables or relations represent objects and contain tuples / rows that all have the same columns / attributes. While this is a logical way to keep data organized, it is limiting in that you can only look at information from one object or source at a time. In order to leverage your data and answer meaningful questions you often need information from multiple tables.
A relational database is ideal for this type of work. It is organized so that various tables can be easily linked together by columns / attributes that they share. These common columns are keys. There are two types of keys, primary and foreign. A primary key is unique to a tuple. In other words, there cannot be duplicates in the column if it is specified as the table’s primary key. Not all tables have to have a primary key, but it is good practice to declare one. A foreign key is a column in a table that matches a primary key in a different table. Foreign keys do not need to be distinct, aka there can be duplicates in a table. The presence of foreign keys in tables allows for joining.
When joining tables it is important to know the relationship between them as it will affect the results that you get. There are three types of relationships that can exist between two tables (table A and B):
One-to-One – one row from A maps to one row from B and one row from B maps to one row from A
One-to-Many – many rows from B are associated with one row in A
- e.g. one BBL may have many DOB Violations, but a DOB Violation can only be associated with one BBL.
Many-to-Many – many rows from B are associated with many rows in A and many rows in A are associated with many rows in B
The below example contains a one-to-many relationship, with primary keys in both tables and a foreign key in the right-hand table.
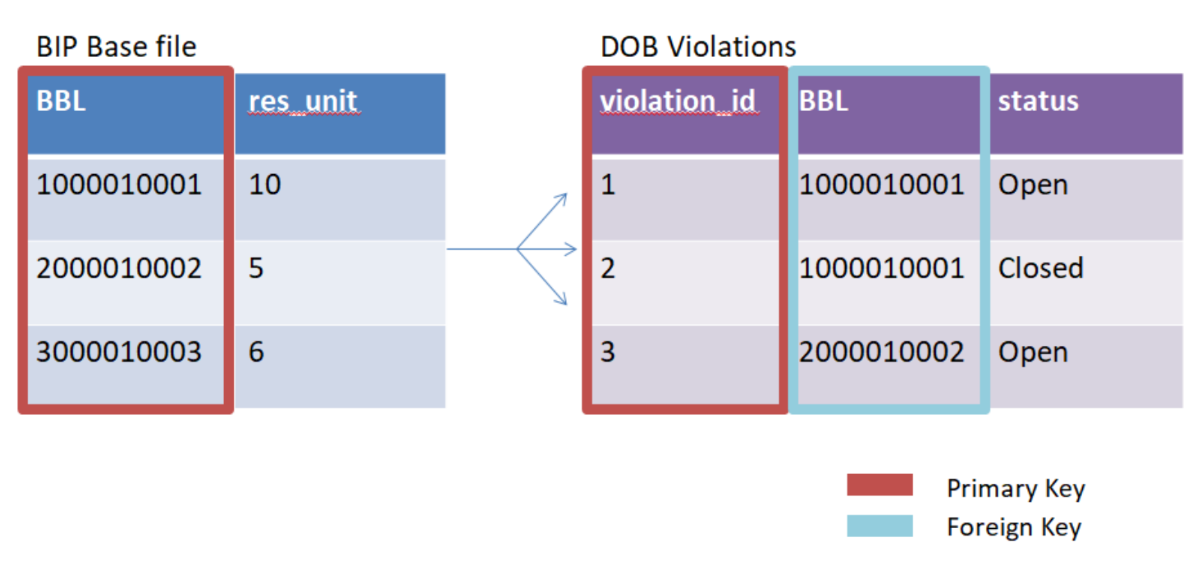
Considering the grain of the data is helpful when trying to determine the type of relationship between two tables. Grain refers to the level of detail that is stored in a table. When joining two tables with different grains you are likely dealing with a One-to-Many relationship. For example, the BIP basefile table is organized by BBL (borough-block-lot). The PAD table is organized by BIN (building identification number). BIN is a finer grain than BBL, as it refers to specific buildings of which there may be many within a single tax lot. For this reason, there is a One-to-Many relationship between the Base file table and the PAD table.
Another element that will affect the results of your query is the type of join that you use. Joins dictate what rows are returned. There are three main types of joins.
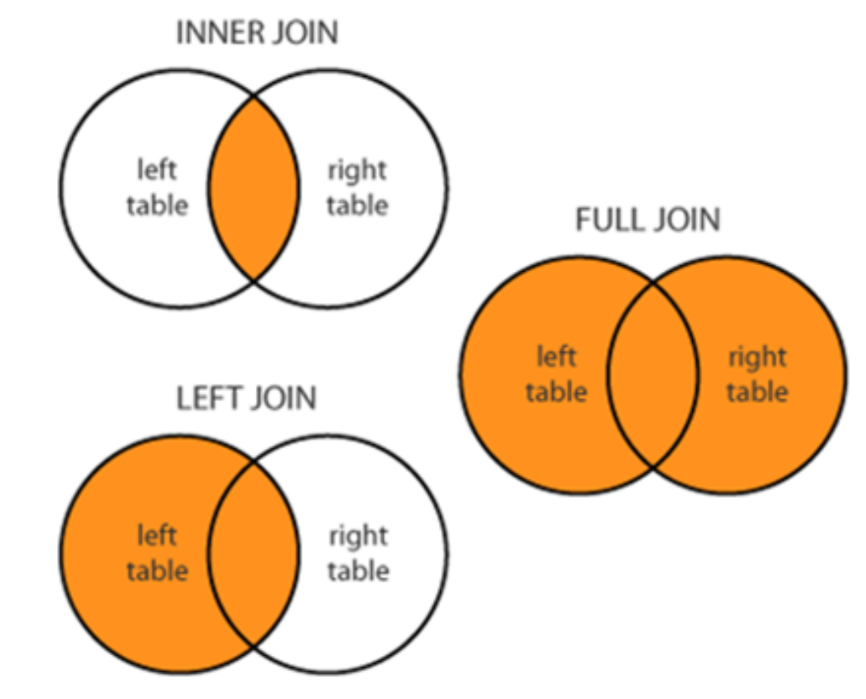
Inner – only return rows where the key has a match in both tables
Left – all the rows from the left table, adds columns from the right table where the key has a match
Full Outer – returns all of the rows from both the left and the right table
Important Query Syntax
- Parts of a Query
1. SELECT – the columns that will be returned
2. FROM – the left-most table, it sets the grain
3. JOIN – the table being joined to the left-most table
4. WHERE – filter when there are no aggregations
5. GROUP BY – columns that aggregations are rolled up to
6. HAVING – filter when aggregating
7. ORDER BY – sort applied to results
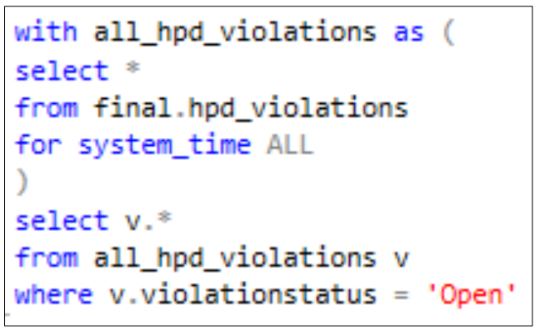
- CTE
Common Table Expressions are useful when trying to build complex queries. They are an alternative to sub/nested queries which require a lot of computing power. CTE’s allow you to create “building blocks” that are stored in memory. You are then able to query from these “building blocks”.
- System-Versioned
If you only want to query the current table you do not need to do anything special. If you want to query from both the current and historical tables you need to include for system_time ALL. It works best if you do this in a CTE. See image in CTE section above.
- Cast
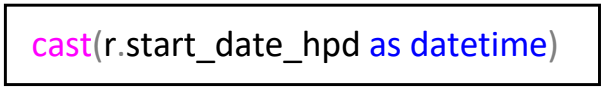
Use this to change the datatype of a column in your query.
- DateAdd
Use this to add or subtract time from a date. You can change the day, the month, and the year. We often use this in conjuncture with cast because we use the nvarchar datatype by default.

- Over & Partition by
Use so that you can retrieve aggregated and non-aggregated columns in the same query. If you use a group by to aggregate based on BBL or another column you must aggregate all of the other columns you select in the query.
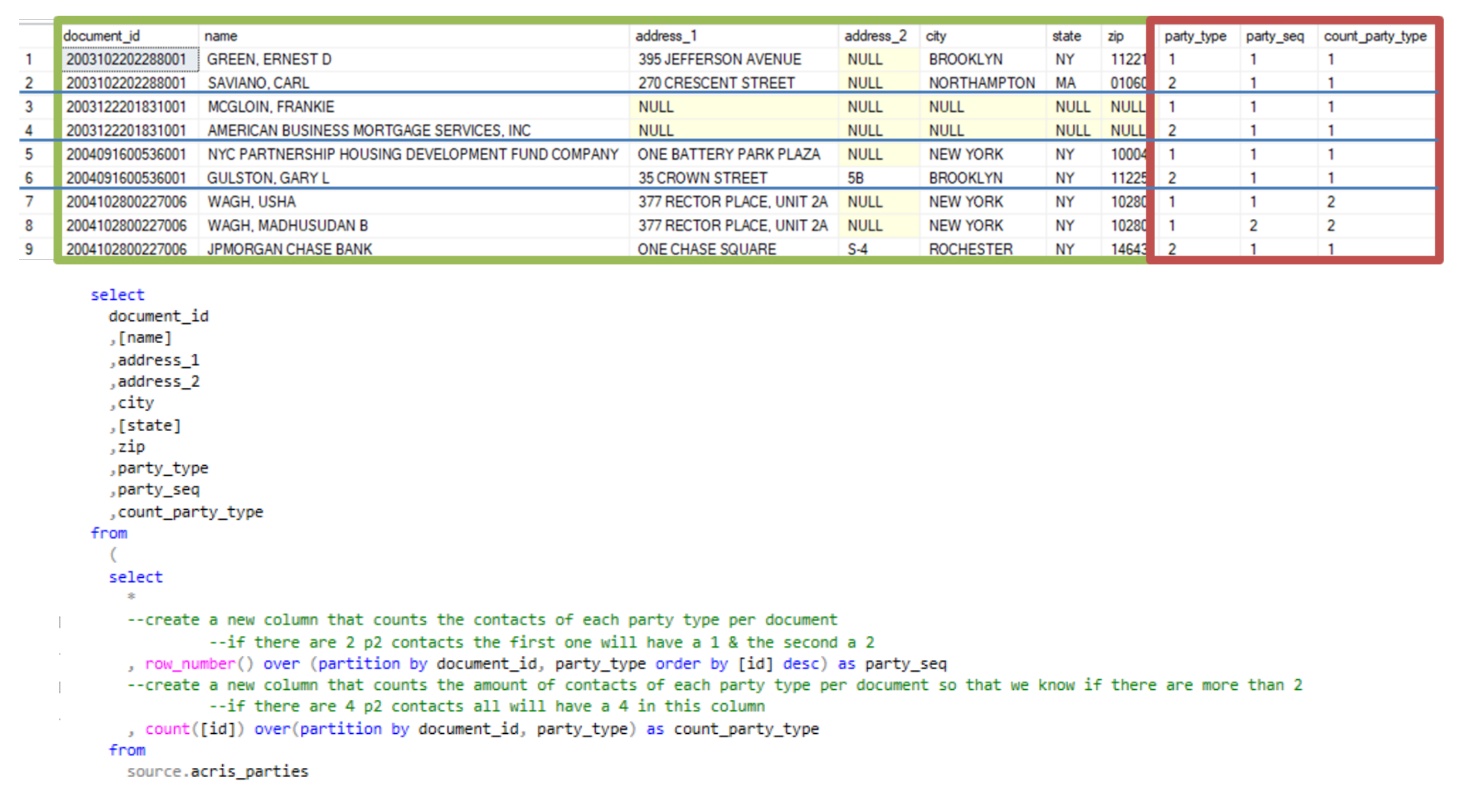
We often use the over and partition by syntax when we need to sequence rows. Below is an example where the over partition by syntax is used to return contacts associated with ACRIS documents. There are two party types associated with documents in ACRIS, party 1 and party 2. There can be multiple contacts of each party type, and each contact will have their own row in the Parties table. We are interested in the first two contacts of each party type – p1_a, p1_b, p2_a, and p2_b. We partition by the [document_id] and the [party_type] which is analogous to grouping by these columns. Then, the row_number is applied to the partitioned dataset to create the [party_seq]. This column counts how many contacts of each [party_type] there are for each [document_id]. We can then use this to select the first two contacts of each type for every ACRIS document.
- e.g. – etl.create_acris_stage : [party_seq] and [count_party_type] are aggregated while the other columns are not.